[Do it! 강의 정리] 자료구조
2023. 8. 4. 15:08ㆍ알고리즘
320x100
배열과 리스트
자료 구조영역에서 자료를 담는데 사용하는 매우 기본적인 자료구조
- 파이썬에서는 리스트가 배여르이 특성도 함께 내포하고 있어 크게 구분하여 사용하지 않음
배열과 리스트의 핵심 이론
배열
메모리의 연속 공간에 값이 채워져 있는 형태의 자료구조.

특징
- 배열의 값은 인덱스를 통해 참조 => 인덱스로 값에 바로 접근할 수 있음
- 선언한 자료형의 값만 저장할 수 있음 => 값을 삽입하거나 삭제하려면 해당 인덱스 주변에 있는 값을 이동시키는 과정이 필요함
- 새로운 값을 삽입하거나 특정 인덱스에 있는 값을 삭제하기 어려움
- 배열의 크기는 선언할 때 지정할 수 있고, 한번 선언하면 크기를 늘리거나 줄일 수 없음.
리스트
값과 포인터를 묶은 노드라는 것을 포인터로 연결한 자료구조
노드 : 컴퓨터 과학에서 값, 포인터를 쌍으로 갖는 기초 단위
특징
- 인덱스가 없어, 값에 접근하려면 Head 포인터부터 순서대로 접근해야 함 => 값에 접근하는 속도가 느림
- 포인터로 연결되어 있으므로 데이터를 삽입하거나 삭제하는 연산속도가 빠름
- 선언할 때 크기를 별도로 지정하지 않아도 됨 => 크기가 정해져있지 않으며 크기가 변하기 쉬운 데이터를 다룰 때 적절함
- 포인터를 저장할 공간이 필요함으로 배열보다 구조가 복잡함
구간 합
배열을 이용하여 시간 복잡도를 더 줄이기 위해 사용하는 특수한 목적의 알고리즘
구간 합의 핵심 이론
구간 합 알고리즘을 활용하려면 먼저 합 배열을 구해야 함
합 배열
S[i] = A[0] + A[1] + ... + A[i-1] + A[i] = S[i-1]+ A[i]구간 합
S[j] - S[i-1] // i에서 j까지 구간 합배열이 자주 변경되는 경우 구간 합은 세그먼트 트리(인덱스 트리)를 사용
스택과 큐
스택과 큐는 리스트에서 조금 더 발전한 형태의 자료구조
스택과 큐의 핵심 이론
스택
삽입과 삭제 연산이 후입선출(LIFO, Last-in First-out)로 이뤄지는 자료구조
- 후입선출은 삽입과 삭제가 한 쪽에서만 일어나는 특징
새로운 값이 스택에 들어가게 되면 top이 새로운 값을 가리키게 됨
값을 삭제할 때 pop은 top이 가리키는 값을 스택에서 빼게 되어있음 -> 가장 마지막에 넣었던 값이 나오게 됨
파이썬에서는 리스트를 이용하여 쉽게 스택을 구현할 수 있음
위치
- top : 삽입과 삭제가 일어나는 위치
연산(리스트 이름 : s)
- s.append(data): top위치에 새로운 데이터를 삽입하는 연산
- s.pop() : top위치에 현재 있는 데이터를 삭제하고 확인하는 연산
- s[-1] : top위치에 현재 있는 데이터를 단순 확인하는 연산
스택은 깊이 우선 탐색(DFS), 백트래킹 종류의 코딩 테스트에 효과적
큐
큐는 삽입과 삭제 연산이 선입선출(FIFO)로 이뤄지는 자료구조. 삽입과 삭제가 양방향에서 이뤄지게 됨
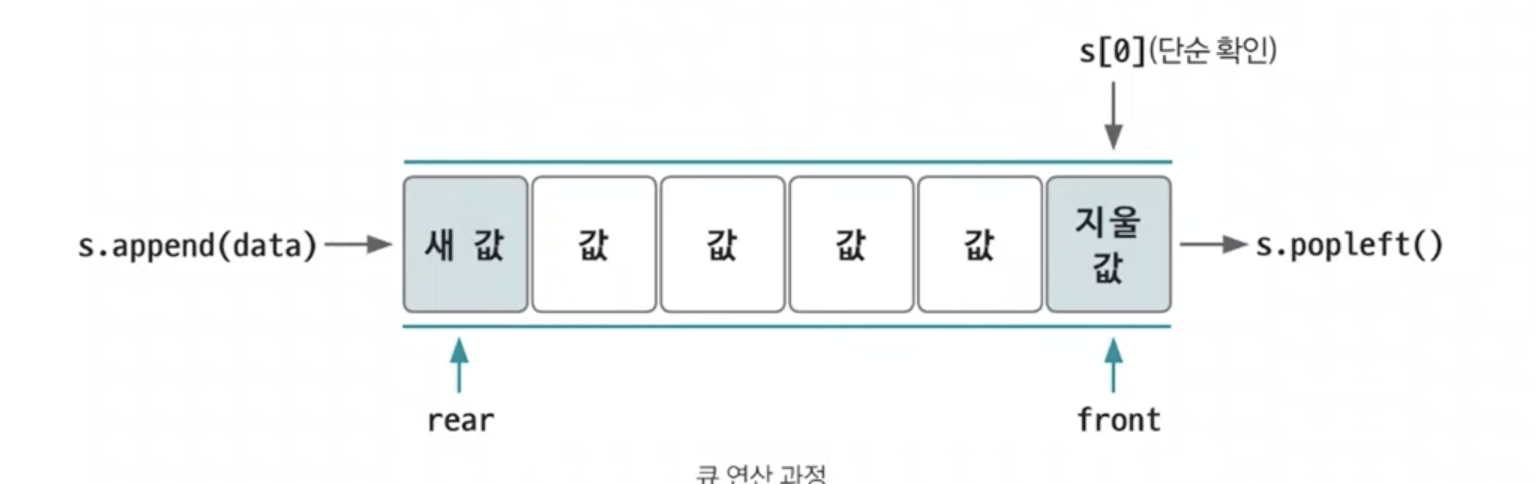
새 값의 추가는 큐의 rear에서 이뤄지고, 삭제는 큐의 front에서 이뤄진다.
파이썬에서는 일반적으로 deque를 이용하여 큐를 구현함.
위치
- rear : 큐에서 가장 끝 데이터를 가리키는 영역
- front : 큐에서 가장 앞의 데이터를 가리키는 영역
연산(리스트 이름 : s)
- s.append(data) : rear 부분에 새로운 데이터를 삽입하는 연산
- s.popleft() : front부분에 있는 데이터를 삭제하고 확인하는 연산
- s[0] : 큐 맨 앞(front)에 있는 데이터를 확인할 때 사용하는 연산
큐는 너비 우선 탐색에서 자주 사용
우선 순위 큐
값이 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 나오는 자료구조
큐 설정에 따라 front에 항상 최댓값 또는 최솟값이 위치함
일반적으로 힙(heap)을 이용해 구현함
728x90
'알고리즘' 카테고리의 다른 글
| [문제 풀이] 오큰수 구하기 (0) | 2023.08.05 |
|---|---|
| [Do it! 강의 정리] 시간복잡도 (0) | 2023.08.04 |
| [Do it! 알고리즘 코딩테스트 with Python] 공부 이유 및 목표 (0) | 2023.08.01 |